StyleGAN-NADA can convert real images between domains, enabling out-of-domain image editing.

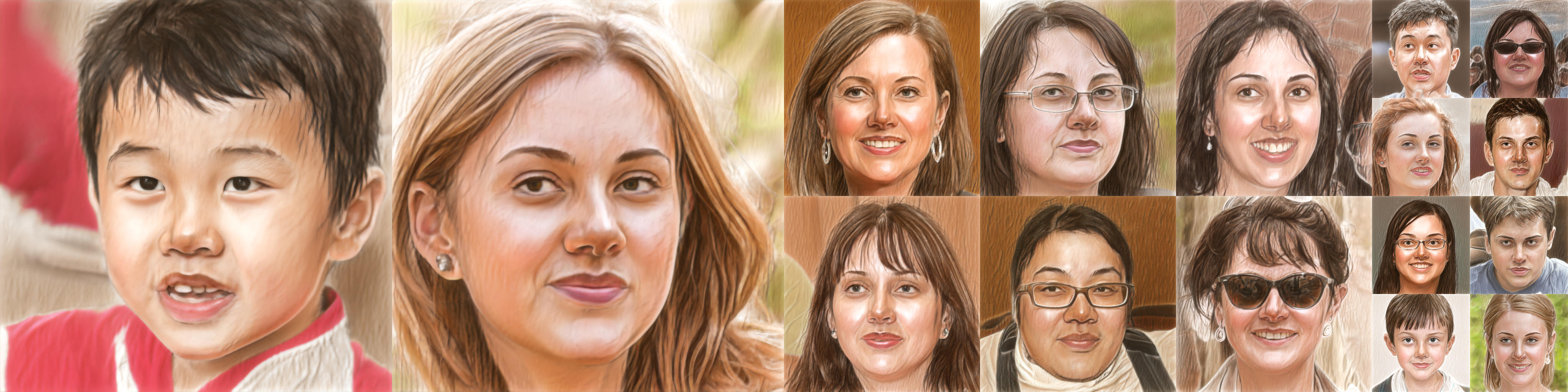

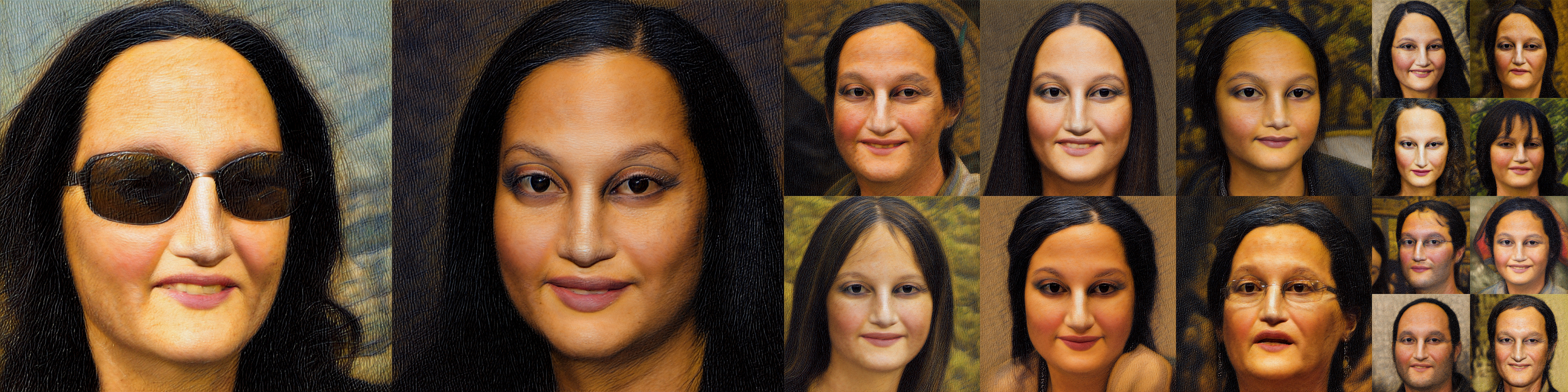






































Can a generative model be trained to produce images from a specific domain, guided by a text prompt only, without seeing any image? In other words: can an image generator be trained blindly?
Leveraging the semantic power of large scale Contrastive-Language-Image-Pre-training (CLIP) models, we present a text-driven method that allows shifting a generative model to new domains, without having to collect even a single image from those domains.
We show that through natural language prompts and a few minutes of training, our method can adapt a generator across a multitude of domains characterized by diverse styles and shapes. Notably, many of these modifications would be difficult or outright impossible to reach with existing methods.
We conduct an extensive set of experiments and comparisons across a wide range of domains. These demonstrate the effectiveness of our approach and show that our shifted models maintain the latent-space properties that make generative models appealing for downstream tasks.
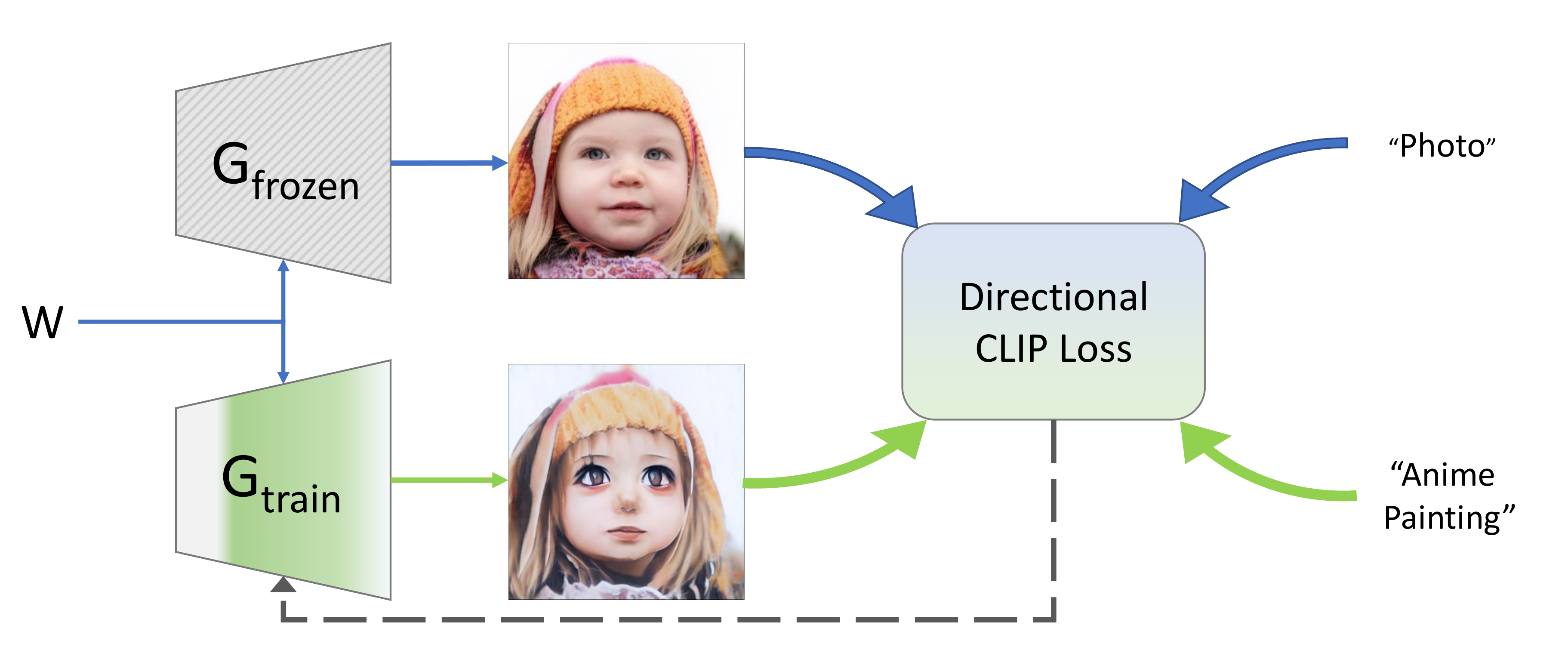
We start with a pre-trained generator and two text prompts describing a direction of change ("Dog" to "Cat"). Instead of editing a single image, we use the signal from OpenAI's CLIP in order to train the generator itself. There's no need for training data, and it works fast! How fast? Minutes or less. See below.
StyleGAN-NADA can convert real images between domains, enabling out-of-domain image editing.
Since we train a new generator - you can even edit the images in the new domain, using your favorite off-the-shelf StyleGAN editing methods.


Methods like pSp already allow for image-to-image translation from arbitrary input domains, but their output is restricted to the domain of a pre-trained GAN. StyleGAN-NADA greatly expands the range of available GAN domains, enabling a wider range of image-to-image translation tasks such as sketch-to-drawing.
Our models and latent spaces are well aligned, so we can freely interpolate between the model weights in order to smoothly transition between domains. We can even apply latent space editing at the same time, creating videos like the one below.
Our work focused on StyleGAN, but it can just as easily be applied to other generative architectures. For example, we can take models that convert segmentation masks to images, such as OASIS, and completely replace the identity of a class - using nothing but text!

If you find our work useful, please cite our paper:
@misc{gal2021stylegannada,
title={StyleGAN-NADA: CLIP-Guided Domain Adaptation of Image Generators},
author={Rinon Gal and Or Patashnik and Haggai Maron and Gal Chechik and Daniel Cohen-Or},
year={2021},
eprint={2108.00946},
archivePrefix={arXiv},
primaryClass={cs.CV}
}